Showing posts with label interview questions. Show all posts
1.Compare SAP HANA & Oracle
| Criteria | SAP HANA | Oracle |
| Strengths | Customization, customer service & functionality | Ease of use, quick deployment and flexibility |
| Compatibility to work with other databases | Very Good | Average |
| Comparison on costs | More cost for internal resources and training | Much lesser on both fronts |
2.What is SAP HANA?
SAP HANA is an in-memory computing engine (IMCE) used for real-time processing of huge volumes of data and building and deploying real-world applications. Adopting the row-based and column-based DB technology, SAP HANA is an advanced relational DB product serviced by SAP SE. With this high-performance analytic (HANA) system, the big data exists on the main memory and not on the hard disk. It replaces the onus of data maintenance separately on the legacy system and simplifies the tasks of administrators in this digital world.Go through this SAP HANA Tutorial to get a clear understanding of how SAP HANA works.
3.What is the development language used by SAP HANA?
C++
4.Name the operating system SAP HANA supports.
More than 70% of customers run their SAP workloads on Linux with the use of SUSE Linux Enterprise Server, which is the best OS choice for SAP HANA.
5.Explain Parallel Processing in SAP HANA?
Using the columnar data storage approach, the workload in SAP HANA is divided vertically. The columnar approach allows linear searching and aggregation of data rather than two-dimensional data structure. If more than one column is to be processed, each task is assigned to diverse processor. Operations on one column are then collimated by column divisions processed by different processors.
6.List advantages of using SAP HANA database.
• With the HANA technology, you can create gen-next applications giving effective and efficient results in the digital economy.
• By using singe data-in memory, SAP HANA supports smooth transaction process and fault-tolerant analytics
• Easy and simple operations using an open-source, unified platform in the cloud
• High-level Data Integration to access massive amounts of data
• Advanced tools for in-depth analysis of present, past and the future.Interested in learning SAP HANA? Well, we have the comprehensive Sap Hana Course to give you a head start in your career.
• By using singe data-in memory, SAP HANA supports smooth transaction process and fault-tolerant analytics
• Easy and simple operations using an open-source, unified platform in the cloud
• High-level Data Integration to access massive amounts of data
• Advanced tools for in-depth analysis of present, past and the future.Interested in learning SAP HANA? Well, we have the comprehensive Sap Hana Course to give you a head start in your career.
7.List the merits and demerits of using row-based tables.
Merits:
• No data approach can be faster than row-based if you want to analyze, process and retrieve one record at one time.
• Row-based tables are useful when there is specific demand of accessing complete record.
• It is preferred when the table consists of less number of rows.
• This data storage and processing approach is easier and effective without any aggregations and fast searching.Demerits:
• The data retrieval and processing operations involve the complete row, even though all the information is not useful.
• No data approach can be faster than row-based if you want to analyze, process and retrieve one record at one time.
• Row-based tables are useful when there is specific demand of accessing complete record.
• It is preferred when the table consists of less number of rows.
• This data storage and processing approach is easier and effective without any aggregations and fast searching.Demerits:
• The data retrieval and processing operations involve the complete row, even though all the information is not useful.
8.List advantages of column-based tables.
• Allows smoother parallel processing of data as the data in columns is stored vertically. Thus, to access data from multiple columns, every operation can be allocated to a separate processor core.
• Only specific columns need to be approached for Select query and any column can be used for indexing.
• Efficient operations since most columns hold unique values and thus, high compression rate.
• Only specific columns need to be approached for Select query and any column can be used for indexing.
• Efficient operations since most columns hold unique values and thus, high compression rate.
9. What table type is preferred in SAP HANA Administration: column-based or row-based?
Since analytic applications require massive aggregations and agile data processing, column-based tables are preferred in SAP HANA as the data in column is stored consequently, one after the other enabling faster and easier readability and retrieval. Thus, columnar storage is preferred on most OLAP (SQL) queries. On the contrary, row-based tables force users to read and access all the information in a row, even though you require data from few and/or specific columns.
10.What is the main SAP HANA database component?
Index Server consists of actual data engines for data processing including input SQL and MDX statements and performs authentic transactions.
11.Explain the concept of Persistence Layer.
The persistence layer in SAP HANA handles all logging operations and transactions for secured backup and data restoring. This layer manages data stored in both rows and columns and provides steady savepoints. Built on the concept of persistence layer of SAP’s relational database, it ensures successful data restores.
Besides managing log data on the disk, HANA’s persistence layer allows read and write data operations via all storage interfaces.
Besides managing log data on the disk, HANA’s persistence layer allows read and write data operations via all storage interfaces.
12.Define Modeling Studio in SAP Hana Administration.
Modeling Studio is an operational tool in SAP HANA based on Eclipse development and administration, which includes live project creation.
• The SAP HANA Studio further builds development objects and deploys them, to access and modify data models like HTML and JavaScript files.
• It also handles various data services to perform data input from SAP warehouse and other related databases.
• Responsible for scheduling data replication tasks.
• The SAP HANA Studio further builds development objects and deploys them, to access and modify data models like HTML and JavaScript files.
• It also handles various data services to perform data input from SAP warehouse and other related databases.
• Responsible for scheduling data replication tasks.
13.List the different compression techniques in HANA?
• Run-length encoding
• Cluster encoding
• Dictionary encoding
• Cluster encoding
• Dictionary encoding
14.Explain SLT
SLT expands to SAP Landscape Transformation referring to trigger –based replication. SLT replication permits data transfer from source to target, where the source can be SAP or non-SAP while the target system has to be SAP HANA with HANA database. Users can accomplish data replication from multiple sources. The three replication techniques supported by HANA are:
• SLT
• SAP Business Objects Data Services (BODS)
• SAP HANA Direct Extractor Connection (DXC)
• SLT
• SAP Business Objects Data Services (BODS)
• SAP HANA Direct Extractor Connection (DXC)
15. Name the replication jobs in SAP HANA.
• Master Job (IUUC_MONITOR_)
• Data Load Job (DTL_MT_DATA_LOAD__)
• Master Controlling Job (IUCC_REPLIC_CNTR_)
• Migration Object Definition Job (IUCC_DEF_MIG_OBJ_)
• Access Plan Calculation Job (ACC_PLAN_CALC__)
• Data Load Job (DTL_MT_DATA_LOAD__)
• Master Controlling Job (IUCC_REPLIC_CNTR_)
• Migration Object Definition Job (IUCC_DEF_MIG_OBJ_)
• Access Plan Calculation Job (ACC_PLAN_CALC__)
16. What is Latency?
The time duration to perform data replication starting from the source to the target system is known as latency.
17.What are the various components of SAP HANA Administration?
• SAP HANA Studio
• SAP HANA Application Cloud
• SAP HANA Cloud
• Sap HANA DBThe Sap Hana Training Videos and Certification Course can open the doors to a stellar career for you.
• SAP HANA Application Cloud
• SAP HANA Cloud
• Sap HANA DBThe Sap Hana Training Videos and Certification Course can open the doors to a stellar career for you.
18.How to perform backup and recovery operations?
During a regular operation, data is by default stored to the disk at savepoints in SAPHANA. As soon a there is any update and transaction, logs become active and get saved from the disk memory. In case of power failure, the database restarts like any other DB returning to the last savepoint log state. SAP HANA requires backup to protect against disk failure and reset DB to the previous state. The backups simultaneously as the users keep performing their tasks.
19.Define SLT Configuration
Configuration is the meaningful information to establish a connection between source, SLT system and SAP HANA architecture as stated in the SLT system. Programmers are allowed to illustrate a new Configuration in Configuration and Monitoring Dashboard.
20.What is Stall?
The waiting process for data to load from the main memory to the CPU cache is called Stall.
21.Define different types of information views.
There are primarily three types of information views in SAP HANA, which are all non-materialized.
• Attribute view
• Analytic view
• Calculation View
• Attribute view
• Analytic view
• Calculation View
22.What are Configuration and Monitoring dashboard?
They are SLT Replication Application Servers to provide configuration information for data replication. This replication status can also be monitored.
23.What is logging table?
Logging table records all replicated changes in the table, which can be further replicated to the target system.
24.How to define Transformation rules in HANA?
Using advanced replication settings, transformation rules are specified to transfer data from source tables during replication process. For instance, setting rules to covert fields, fill vacant fields and skip records. These rules are structured using advanced replication settings (transaction IUUC_REPL_CONT)
25.Explain the role of transaction manager and session?
SAP HANA transaction manager synchronizes database transactions keeping the record of closed and open transactions. When a transaction is committed or rolled back, the manager informs all the active stores and engines about the action so that they can perform required actions in time.
26.How is SQL statement processed in SAP HANA?
Each SQL statement in SAP HANA is carried out in the form of a transaction. Every time, a new session is allocated to a new transaction.
27. Define Master-Controller job.
A Master-controller job is responsible to build database logging table in the source system. It further creates synonyms and new entries in SLT server admin when the table loads / replicates.
28.How users can avoid un-necessary storage of logging information?
Pause the replication process and terminate the schema-related jobs.
29.Is the table size in source system and Sap HANA system same?
No
30.When to change the number of Data Transfer Jobs?
The number of data transfer jobs change when the initial loading speed or latency replication time is not up to the mark. At the end of the initial load, the number of initial load jobs may be reduced.
31.What is the default IMCE Studio perspective?
Administrator ConsoleTake charge of your career by going through our professionally designed Sap Hana Certification Course now
Qs. Why SAP HANA is fast?
-------------------------------------------------------------------------------------------------------------------------
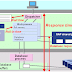
Qs. Describe SAP HANA Database Architecture in brief.
--------------------------------------------------------------------------------------------------------------------------
The SAP HANA database is developed in C++ and runs on SUSE Linux Enterpise Server. SAP HANA database consists of multiple servers and the most important component is the Index Server. SAP HANA database consists of Index Server, Name Server, Statistics Server, Preprocessor Server and XS Engine.
Index Server:
Index Server:
- Index server is the main SAP HANA database component
- It contains the actual data stores and the engines for processing the data.
- The index server processes incoming SQL or MDX statements in the context of authenticated sessions and transactions.
The database persistence layer is responsible for durability and atomicity of transactions. It ensures that the database can be restored to the most recent committed state after a restart and that transactions are either completely executed or completely undone.
Preprocessor Server:
The index server uses the preprocessor server for analyzing text data and extracting the information on which the text search capabilities are based.
Name Server:
The name server owns the information about the topology of SAP HANA system. In a distributed system, the name server knows where the components are running and which data is located on which server.
Statistic Server:
The statistics server collects information about status, performance and resource consumption from the other servers in the system.. The statistics server also provides a history of measurement data for further analysis.
Session and Transaction Manager:
The Transaction manager coordinates database transactions, and keeps track of running and closed transactions. When a transaction is committed or rolled back, the transaction manager informs the involved storage engines about this event so they can execute necessary actions.
XS Engine:
XS Engine is an optional component. Using XS Engine clients can connect to SAP HANA database to fetch data via HTTP.
Qs.What is ad hoc analysis?
-----------------------------------------------------------------------------------------------------------------------
In traditional data warehouses, such as SAP BW, a lot of pre-aggregation is done for quick results. That is the administrator (IT department) decides which information might be needed for analysis and prepares the result for the end users. This results in fast performance but the end user does not have flexibility.
The performance reduces dramatically if the user wants to do analysis on some data that is not already pre-aggregated. With SAP HANA and its speedy engine, no pre-aggregation is required. The user can perform any kind of operations in their reports and does not have to wait hours to get the data ready for analysis.
The performance reduces dramatically if the user wants to do analysis on some data that is not already pre-aggregated. With SAP HANA and its speedy engine, no pre-aggregation is required. The user can perform any kind of operations in their reports and does not have to wait hours to get the data ready for analysis.
Qs. What is SAP HANA?
SAP HANA is an in-memory database.
An in-memory database means all the data is stored in the memory (RAM). This is no time wasted in loading the data from hard-disk to RAM or while processing keeping some data in RAM and temporary some data on disk. Everything is in-memory all the time, which gives the CPUs quick access to data for processing.
SAP HANA is equipped with multiengine query processing environment which supports relational as well as graphical and text data within same system. It provides features that support significant processing speed, handle huge data sizes and text mining capabilities.
- It is a combination of hardware and software made to process massive real time data using In-Memory computing.
- It combines row-based, column-based database technology.
- Data now resides in main-memory (RAM) and no longer on a hard disk.
- It’s best suited for performing real-time analytics, and developing and deploying real-time applications.
An in-memory database means all the data is stored in the memory (RAM). This is no time wasted in loading the data from hard-disk to RAM or while processing keeping some data in RAM and temporary some data on disk. Everything is in-memory all the time, which gives the CPUs quick access to data for processing.
SAP HANA is equipped with multiengine query processing environment which supports relational as well as graphical and text data within same system. It provides features that support significant processing speed, handle huge data sizes and text mining capabilities.

To know more, check the article SAP HANA Introduction for Beginners
Qs. So is SAP making/selling the software or the hardware?
SAP has partnered with leading hardware vendors (HP, Fujitsu, IBM, Dell etc) to sell SAP certified hardware for HANA.
SAP is selling licenses and related services for the SAP HANA product which includes the SAP HANA database, SAP HANA Studio and other software to load data in the database.
To know more, check the article SAP HANA Hardware
SAP is selling licenses and related services for the SAP HANA product which includes the SAP HANA database, SAP HANA Studio and other software to load data in the database.
To know more, check the article SAP HANA Hardware
Qs. What is the language SAP HANA is developed in?
The SAP HANA database is developed in C++.
Qs. What is the operating system supported by HANA?
Currently SUSE Linux Enterprise Server x86-64 (SLES) 11 SP1 is the Operating System supported by SAP HANA.
Qs. Can I just increase the memory of my traditional Oracle database to 2TB and get similar performance?
NO.
You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM.
It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
You might have performance gains due to more memory available for your current Oracle/Microsoft/Teradata database but HANA is not just a database with bigger RAM.
It is a combination of a lot of hardware and software technologies. The way data is stored and processed by the In-Memory Computing Engine (IMCE) is the true differentiator. Having that data available in RAM is just the icing on the cake.
Qs. What are the row-based and column based approach?
Row based tables:
Following figure explains the difference between the two storage mechanism.
- It is the traditional Relational Database approach
- It store a table in a sequence of rows
- It store a table in a sequence of columns i.e. the entries of a column is stored in contiguous memory locations.
- SAP HANA is particularly optimized for column-order storage.
Following figure explains the difference between the two storage mechanism.

To know more, check the article Column Data Storage Vs Row Data Storage in HANA
NEXT>2
Subscribe to:
Posts (Atom)